Publications
My publications in reversed chronological order. You could also visit my Google Scholar page.
(* denotes equal contribution)
2023
-
 Extraneousness-Aware Imitation LearningIn IEEE International Conference on Robotics and Automation (ICRA), 2023
Extraneousness-Aware Imitation LearningIn IEEE International Conference on Robotics and Automation (ICRA), 2023Visual imitation learning provides an effective framework to learn skills from demonstrations. However, the quality of the provided demonstrations usually significantly affects the ability of an agent to acquire desired skills. There- fore, the standard visual imitation learning assumes near- optimal demonstrations, which are expensive or sometimes prohibitive to collect. Previous works propose to learn from noisy demonstrations; however, the noise is usually assumed to follow a context-independent distribution such as a uniform or gaussian distribution. In this paper, we consider another crucial yet underexplored setting — imitation learning with task- irrelevant yet locally consistent segments in the demonstrations (e.g., wiping sweat while cutting potatoes in a cooking tutorial). We argue that such noise is common in real world data and term them as “extraneous” segments. To tackle this problem, we introduce Extraneousness-Aware Imitation Learning (EIL), a self-supervised approach that learns visuomotor policies from third-person demonstrations with extraneous subsequences. EIL learns action-conditioned observation embeddings in a self-supervised manner and retrieves task-relevant observations across visual demonstrations while excluding the extraneous ones. Experimental results show that EIL outperforms strong baselines and achieves comparable policies to those trained with perfect demonstration on both simulated and real-world robot control tasks. The project page can be found here: https://sites.google.com/view/eil-website.
@inproceedings{zheng2022extraneous, title = {{Extraneousness-Aware Imitation Learning}}, booktitle = {{IEEE International Conference on Robotics and Automation (ICRA)}}, author = {Zheng*, Ray Chen and Hu*, Kaizhe and Yuan, Zhecheng and Chen, Boyuan and Xu, Huazhe}, year = {2023}, pages = {2973-2979}, doi = {10.1109/ICRA48891.2023.10161521}, langid = {english}, } -
 Decision Transformer under Random Frame DroppingIn The Eleventh International Conference on Learning Representations, 2023
Decision Transformer under Random Frame DroppingIn The Eleventh International Conference on Learning Representations, 2023Controlling agents remotely with deep reinforcement learning (DRL) in the real world is yet to come. One crucial stepping stone is to devise RL algorithms that are robust in the face of dropped information from corrupted communication or malfunctioning sensors. Typical RL methods usually require considerable online interaction data that are costly and unsafe to collect in the real world. Furthermore, when applying to the frame dropping scenarios, they perform unsatisfactorily even with moderate drop rates. To address these issues, we propose Decision Transformer under Random Frame Dropping (DeFog), an offline RL algorithm that enables agents to act robustly in frame dropping scenarios without online interaction. DeFog first randomly masks out data in the offline datasets and explicitly adds the time span of frame dropping as inputs. After that, a finetuning stage on the same offline dataset with a higher mask rate would further boost the performance. Empirical results show that DeFog outperforms strong baselines under severe frame drop rates like 90%, while maintaining similar returns under non-frame-dropping conditions in the regular MuJoCo control benchmarks and the Atari environments. Our approach offers a robust and deployable solution for controlling agents in real-world environments with limited or unreliable data.
@inproceedings{hu2023decision, title = {{Decision Transformer under Random Frame Dropping}}, author = {Hu*, Kaizhe and Zheng*, Ray Chen and Gao, Yang and Xu, Huazhe}, booktitle = {{The Eleventh International Conference on Learning Representations}}, year = {2023}, url = {https://openreview.net/forum?id=NmZXv4467ai}, langid = {english}, }


2019
-
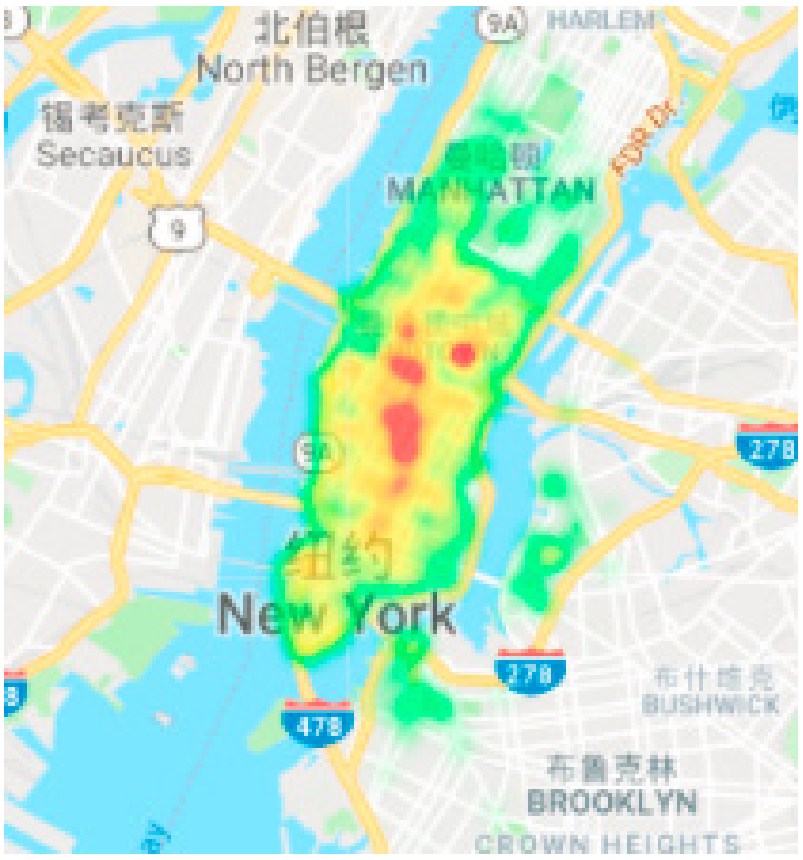 Predicting bike sharing demand using recurrent neural networksProcedia Computer Science, 20192018 International Conference on Identification, Information and Knowledge in the Internet of Things
Predicting bike sharing demand using recurrent neural networksProcedia Computer Science, 20192018 International Conference on Identification, Information and Knowledge in the Internet of ThingsPredicting bike sharing demand can help bike sharing companies to allocate bikes better and ensure a more sufficient circulation of bikes for customers. This paper proposes a real-time method for predicting bike renting and returning in different areas of a city during a future period based on historical data, weather data, and time data. We construct a network of bike trips from the data, use a community detection method on the network, and find two communities with the most demand for shared bikes. We use data of stations in the two communities as our dataset, and train an deep LSTM model with two layers to predict bike renting and returning, making use of the gating mechanism of long short term memory and the ability to process sequence data of recurrent neural network. We evaluate the model with the Root Mean Squared Error of data and show that the prediction of proposed model outperforms that of other deep learning models by comparing their RMSEs.
@article{pan2019predicting, title = {Predicting bike sharing demand using recurrent neural networks}, journal = {Procedia Computer Science}, volume = {147}, pages = {562-566}, year = {2019}, note = {2018 International Conference on Identification, Information and Knowledge in the Internet of Things}, issn = {1877-0509}, doi = {https://doi.org/10.1016/j.procs.2019.01.217}, url = {https://www.sciencedirect.com/science/article/pii/S1877050919302364}, author = {Pan, Yan and Zheng, Ray Chen and Zhang, Jiaxi and Yao, Xin}, keywords = {Shared bike demand prediction, time series forecasting, recurrent neural networks, long short term memory}, }
